
Augmented Instruments Lab: April Dev Update
Forming a new kind of microtonal vocal musical instrument

For context, I’m a Ph.D. Student at Imperial College at the Augmented Instruments Lab, a music technology research team led by Prof. Andrew McPherson. I’m in the first year of my studies, and I’ve decided to explore instrumentation around the intersection of transgender vocal training and microtonal synthesis. I’m building upon my work from the past year in microtonal synthesis, called Ephemerides, and the voice training I’ve taken on independently of musical practice.
Version 1 of Ephemerides is here, in which I used the Bela platform to code a microtonal synthesizer in C++.
Version 2 is a VST Synth Plugin using the same code, written in CMajor, yet to be released.
This blog post is about Version 3, which I’m now figuring out.
Try 1: SuperCollider Digital Synthesis
In early march I was exploring vowel synthesis in SuperCollider and the knowledge around formant construction, as an obvious intersection of trans voice studies and things I can measure and also has musical significance. More info on formants here.
I already use the vowel library in SuperCollider in my live coding with Tidalcycles, and I found out that the formants in the library are pre-determined, and they’re based on the standard soprano, alto, tenor, and bass classification system.
Source Code for those interested
SuperCollider seemed like the ideal environment to think about exploring microtonality, spectral synthesis, and spectral analysis. There’s lots of tools and Unit Generators that seem to have what I was looking for. There’s a real-time LPC Analysis UGen, guides on constructing tuning systems with or without MIDI, and general resources about using the Fast Fourier Transform for spectral synthesis. But, if I want to do anything signal processing related, beyond what was given, I'd have to recompile the UGens for that purpose. That involves going into creating a C++ development environment in XCode, reading SuperCollider UGen code, and making sense of it, then figuring out how to code my own thing.
I found the whole process to be a bit of a headache, finding dead ends at almost every turn. Writing code in SuperCollider is tough, it’s a LISP-based language with many idiosyncrasies. The LPC Analysis to find formants didn’t go very far as I didn’t have access to any of the internal data within the UGen!
While I was in it, I played around with using FFT analysis to identify local maxima (peak frequencies), isolate the top 10, and convert that back to playable sound. Code and recordings below:
Example 1: Spectral Freezing on Local Maxima as an interaction
Example 2: On a full choral sound
(
SynthDef("help-localMax2", { arg out=0, soundBufnum=2;
var in, chain, kbus, binIndex, binFreqs, activeFreqs;
// Generate bin indices
binIndex = Array.fill(512, { |i| i });
// Convert to frequency (binIndex * sampleRate / fftSize)
binFreqs = binIndex * (SampleRate.ir / 1024);
in = PlayBuf.ar(1, soundBufnum, BufRateScale.kr(soundBufnum), loop: 1);
chain = FFT(LocalBuf(2048), in);
chain = PV_LocalMax(chain, 10);
chain = PV_Freeze(chain, MouseY.kr(-1, 1));
activeFreqs = Select.kr(chain, binFreqs);
// get the values and send to bus
// Out.k(0, activeFreqs);
Out.ar(out, 0.9 * IFFT(chain).dup);
}).play(s, [\soundBufnum, d]);
)
Notice how you can pick on some of the individual sine waves.
Try 2: Additive Synthesis and Filter-Based Feedback in MaxMSP
My discussions with Andrew addressed the more practical concerns: How does microtonality and voice mesh together in an interesting way? The voice can't just imagine microtones easily. Even with a lot of training it'd be hard to get something so precise in a musical way. One idea was to use vocal chords with a microtonal resonance spectrum, as if you had an open piano and let string vibrate along with the voice. Another idea was to not use vocal cords at all, letting the vocal tract determine what notes were to emerge out of a spectrum.
We investigated the Clarimate for its alignment on these topics. Clarmate describes itself as "a Reversible Hybrid Instrument and Digital Practice Mute for Bb clarinets". It's functionality is simple: you blow and make the fingerings without sound coming out, and you can hear a simulation of your playing in real time in headphones. The device accomplishes this by playing dozens of sine waves into the instrument and measuring the frequency response that returns. Whatever peak (i.e. sine wave frequency) is the highest, we assume, is the Midi note that's played back to the musician through headphones.



source: https://clarimate.us
Could you use the vocal tract for the same purpose, and if so, do you have to put the speaker into your mouth? In my initial recordings, I was able to track my r1 (larynginal resonance) and r2 (oral resonance) fairly well. Here's some baseline and modified recordings.
What the Clarimate sounds like:
Clarimate positioned in front of my open mouth:
Next I tried attaching a transducer from an 8-ohm speaker directly to my throat to see if I could get the same results. The answer is yes! Recordings below, but with these findings we know it's possible to project additive synthesis into the throat in a non-instrusive way and then treat the throat as a kind of resonant filter to inform microtonal synthesis.
A Recording of the Clarimate, playthrough a transducer pressed to my throat:
Over the past week I'm exploring cloning the Clarimate to some degree, but with Ephemerides, the microtonal synthesizer I built last year. Clarimate's sine waves are the 12-tone equal temperament separation of pitch classes across a frequency spectrum specific to the clarinet. For this instrument I want to give the performer to modulate the pitch classes that are available in real time. This is with or without using the vocal cords, so it's completely irrespective of what pitches you can produce with the vocal tract, focusing on other features of voice like resonance and weight
MaxMSP's mc.gen~ was a lifesaver for this task. The original version of Ephemerides I built in max didn't use multichannel cabling or gen~ so it ended up being a big mess of manually performing every calculation with objects. The gen~ object treats things more like c++ dsp that operates per sample instead of per block, and allows for complex operations to occur based on what channel number is available. The codebox operator also allows for c-like syntax for math and if-else statements which made the process much more straightforward.
Below: What’s being played on the transducer
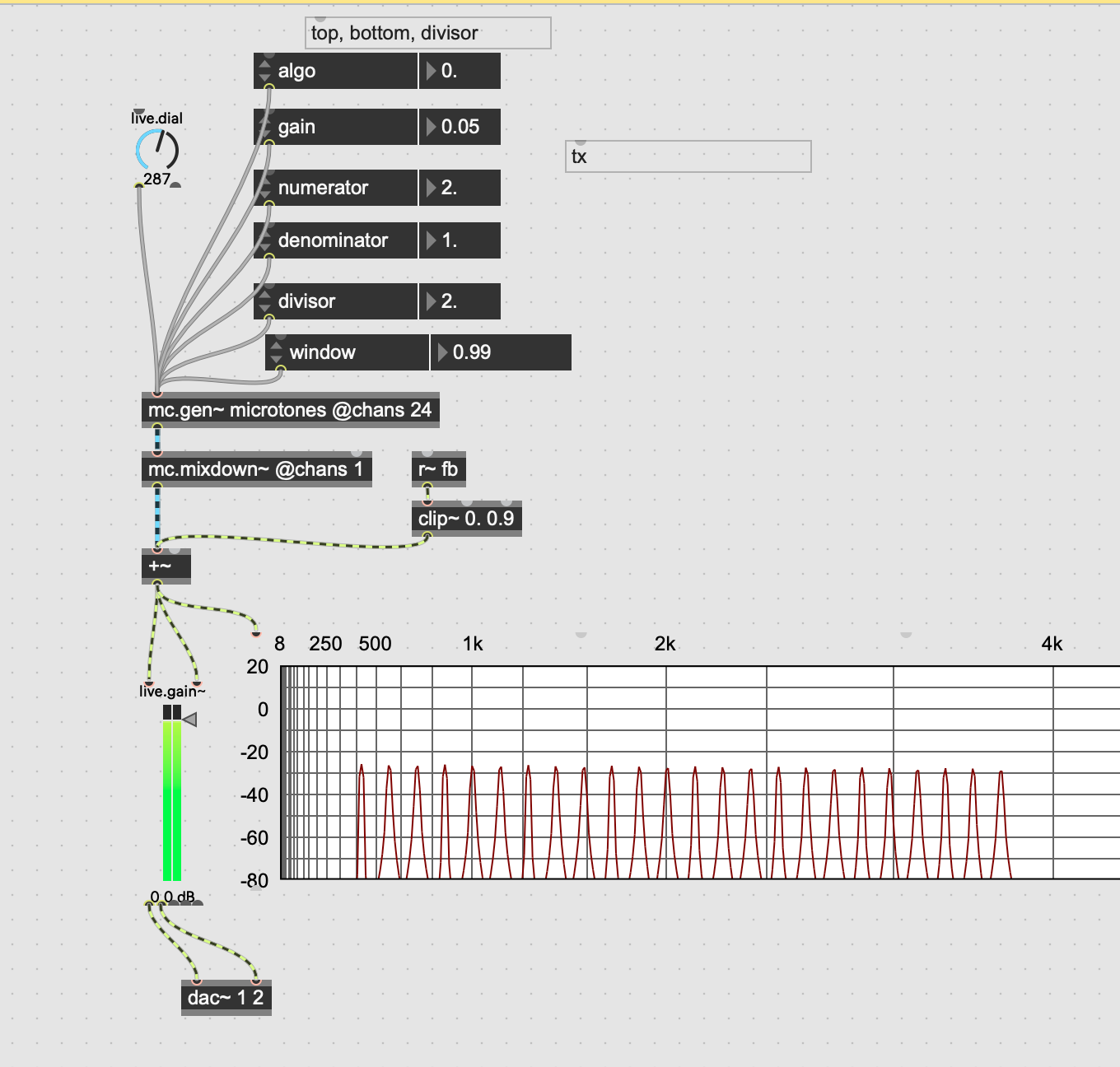
Below: what’s being received by the micophone
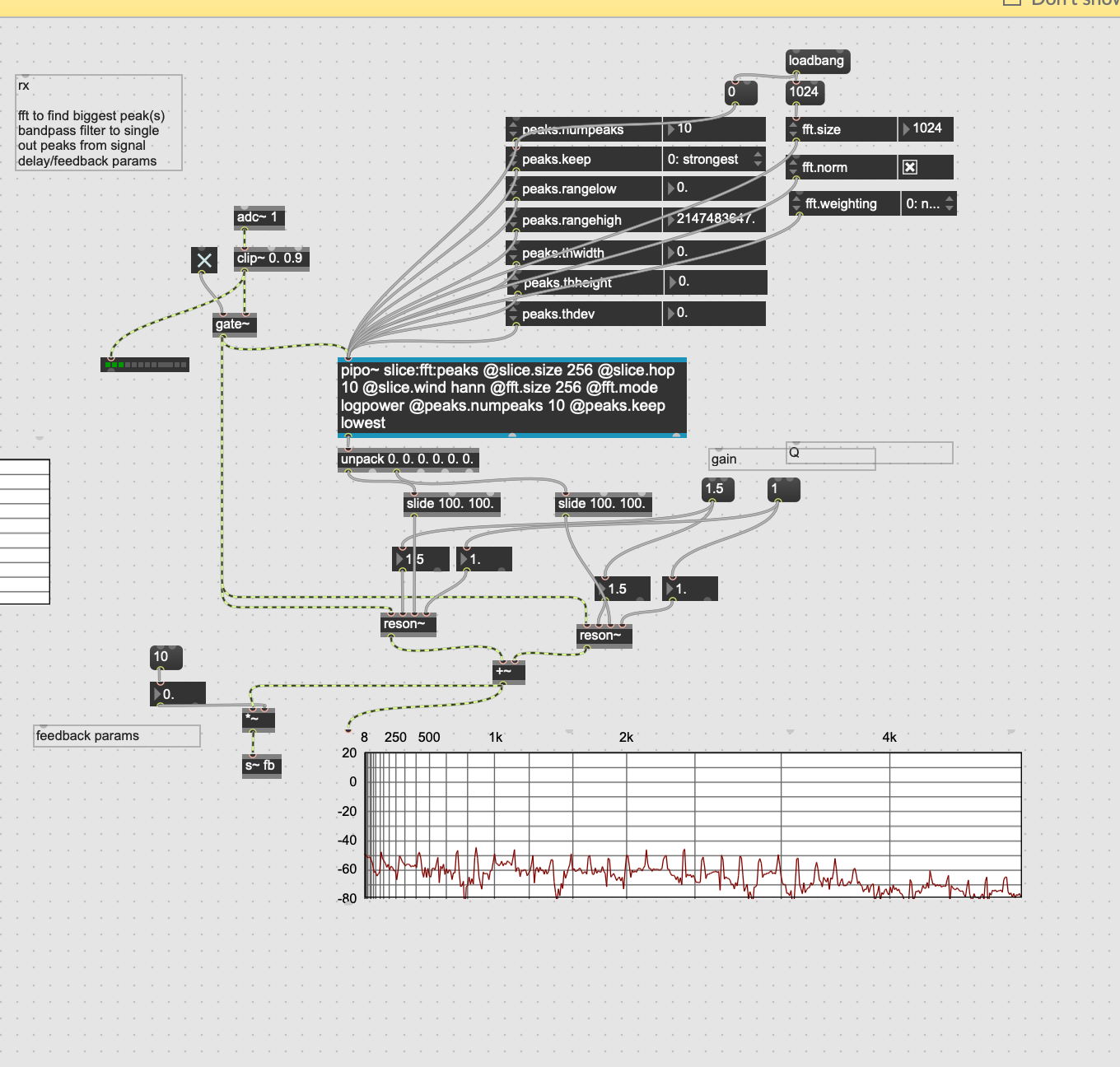
On the receiving end (post-vocal tract) I used the MuBu peak detection algorithm to find the 2-3 highest peaks in terms of frequency and used that as input of a couple of resonant bandpass filters. With a bit of feedback it's like the other frequencies aren't even there. right now I'm just piping audio from my mac into a transducer.
Recordings below:
Without Feedback
High Q Resonance Filter and Feedback
Low Q Resonance Filter Feedback
With a bit more control
Keep in mind I’m not vocalising at all, these are literally just sine waves at different frequencies being accessed by the throat as its own resonant filter.

Next Steps
Is a resonant bandpass filter the way to go? What about using an envelope follower and re-synthesis like the Clarimate?
How is microtonality going to be more intuitive for vocal performers?
Is this instrument destined for noise gigs, or there a more contemporary classical aspiration?
Does this instrument adequately explore gendered characteristics of voice to show gender as a musical expression?